Aplicando Redes Neurais e Estimativa Análoga para Determinar o Orçamento do Projeto
Publicações
PMI Global Congress 2015 – North America
Orlando – Florida – USA – 2015
Resumo
Este artigo procura discutir o uso de Redes Neurais Artificiais (RNAs) para modelar aspectos do orçamento do projeto em casos em que os algoritmos tradicionais e fórmulas não estão disponíveis ou não são de fácil aplicação. Redes neurais usam um processo análogo ao cérebro humano, onde um componente de treinamento é feito a partir de dados existentes e, subsequentemente, têm-se uma rede neural treinada “especialista” na categoria de informação analisada. Esse “especialista” pode, então, ser utilizado para fazer projeções a partir de novas situações baseadas numa aprendizagem adaptativa (STERGIOU & CIGANOS, 1996).
O artigo também apresenta um exemplo fictício que ilustra o uso de redes neurais para determinar o custo das atividades de gerenciamento do projeto de acordo com a complexidade, localização, orçamento, duração e número de stakeholders considerados relevantes. O exemplo baseia-se em dados de 500 projetos e é usado para prever o custo do gerenciamento de um novo projeto.
Redes Neurais Artificiais (RNA)
Algumas categorias de problemas e desafios enfrentados em ambientes de projetos podem depender de vários fatores sutis de tal maneira que um algoritmo computacional não pode ser criado para calcular seu resultado (KRIESEL, 2005). Redes Neurais Artificiais (RNAs) são uma família de modelos estatísticos de aprendizagem cujo funcionamento é inspirado na maneira com que sistemas nervosos biológicos, como o cérebro, processam informação. Eles processam registros um por vez, e “aprendem” comparando os resultados obtidos com os resultados reais previamente conhecidos.
Os erros da classificação inicial do primeiro registro são retroalimentados à rede e são usados para modificar os algoritmos da mesma para a segunda iteração, e assim por diante continua, para um grande número de repetições, num processo de aprendizagem cujo o objetivo é prever resultados confiáveis a partir de dados complicados ou imprecisos (STERGIOU & CIGANOS, 1996) (Figura 01).
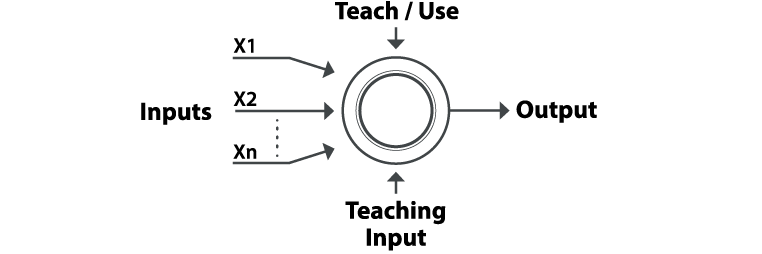 Figura 01 – Arquiteturas de Redes Neurais Artificiais (adaptado de MCKIM, 1993, e STERGIOU & CIGANOS, 1996)
Figura 01 – Arquiteturas de Redes Neurais Artificiais (adaptado de MCKIM, 1993, e STERGIOU & CIGANOS, 1996)
Algumas aplicações típicas das RNAs são:
- • Reconhecimento de escrita;
- • Previsões no mercado de ações;
- • Compressão de imagens;
- • Gerenciamento de riscos;
- • Previsão de vendas;
- • Controle de processos industriais.
O processo matemático que fundamenta os cálculos usa diferentes configurações de redes neurais para um melhor ajuste para as previsões. Os tipos mais comuns de redes são descritos a seguir.
Redes Neurais Probabilísticas (RNP) – Algoritmos estatísticos onde as operações são organizadas em redes multicamadas sem realimentação (“feedforward”). É composta por quatro camadas (entrada, padrão, somas e saída). É treinada mais rapidamente mas possui uma execução mais lenta e requer muita memória. Também não é tão geral quanto as outras redes sem realimentação (CHEUNG & CANNONS, 2002).
Redes Multicamadas sem Realimentação (RMSR) – RMSR, treinadas com algoritmos de aprendizagem com retropropagação (Figura 02). São os modelos mais populares de redes neurais (SVOZIL, KVASNIČKA & POSPÍCHAL, 1997).
 Figura 02 – Dados de treinamento do modelo e generalização em Redes Multicamadas sem Realimentação SVOZIL, D , KVASNIČKA, V. & POSPÍCHAL, J. , 1997)
Figura 02 – Dados de treinamento do modelo e generalização em Redes Multicamadas sem Realimentação SVOZIL, D , KVASNIČKA, V. & POSPÍCHAL, J. , 1997)
Redes Neurais com Regressão Generalizada (RNRR) – Semelhante às RNPs, é uma rede “baseada em memória” (registros prévios) que fornece estimativas para variáveis contínuas. O algoritmo pode ser utilizado para qualquer problema de regressão onde a premissa de linearidade não é justificada (SPECHT, 2002).
Processo de Analogia e Conjunto de Dados
Um dos pontos principais das Redes Neurais é o conjunto de dados usados para o processo de aprendizagem. Se o conjunto não for consistente, os resultados obtidos a partir dos cálculos também não serão. O uso de Redes Neurais Artificiais pode ser considerado um tipo de analogia (BAILER-JONES & BAILER-JONES, 2002).
A analogia é uma comparação entre dois ou mais elementos, tipicamente com o propósito de explicação ou esclarecimento (Figura 03). Um dos mais relevantes usos da analogia é previsão de resultados futuros baseados em resultados similares obtidos em condições similares (BARTHA, 2013). O desafio é entender o que é uma condição similar. Projetos no passado podem ser utilizados como referência para projetos futuros se as condições subjacentes anteriores persistem no cenário atual.
 Figura 03 – Exemplo de uma simples analogia: “meais são para os pés e luvas são para as mãos” (Adaptada de Spitzig, 2013)
Figura 03 – Exemplo de uma simples analogia: “meais são para os pés e luvas são para as mãos” (Adaptada de Spitzig, 2013)
Um dos aspectos mais relevantes da analogia está relacionada com um processo simples de estimativas baseado em fatos e eventos semelhantes. Esse processo reduz a granularidade de todos os cálculos, onde os custos finais do projeto podem ser determinados por uma série de variáveis fixas e finitas.
Conjunto de Dados, Categorias Dependentes e Independentes e Variáveis Numéricas
O primeiro passo para desenvolver uma Rede Neural Artificial é preparar um conjunto básico de dados que será utilizada como referência no “processo de treinamento” da rede neural. É importante salientar que construir um conjunto correto de dados para o processo é usualmente caro e consome tempo (INGRASSIA & MORLINI, 2005). Esse conjunto de dados é composto por uma série de variáveis que formatam a referência do treinamento. Cada composição de variáveis agrupada é chamada de caso (Figura 04).
variables | |||||||||||
inDependent variables | Dependent variable (output) | ||||||||||
v1 | v2 | v3 | vn | v’1 | |||||||
Figura 04 – Estrutura de um conjunto de dados básico | |||||||||||
Cases | Case 1 | ||||||||||
Case 2 | |||||||||||
Case 3 | |||||||||||
Case n | |||||||||||
Os tipos de variáveis mais comuns são:
Dependente Categórica – variável dependente ou saída cujos valores são pertencentes a uma categoria qualquer; por exemplo: Sim ou Não, ou Vermelho, Verde ou Azul;
Dependente Numérica – variável dependente ou saída cujos valores possíveis são numéricos;
Independente Categórica – uma variável independente cujos valores possíveis são pertencentes a uma categoria qualquer; por exemplo: Sim ou Não, ou Vermelho, Verde ou Azul;
Independente Numérica – uma variável independente cujos valores possíveis são numéricos;
Em ambientes de projetos, muitas variáveis podem ser usadas para calcular o orçamento do projeto. Alguns exemplos comuns são:
Complexidade – Nível de complexidade do projeto (Baixa, Média e Alta). Geralmente é de categoria independente;
Local – Local onde o trabalho do projeto irá acontecer. Associada à complexidade do trabalho e da logística do projeto. É, quase sempre, uma de categoria independente.
Orçamento – Orçamento planejado para o projeto. É um valor numérico que pode ser independente e dependente (saída);
Custo Atual – Aquilo que já foi gasto até o presente no projeto. É, quase sempre, uma variável numérica independente;
Variância do Custo – A diferença entre o valor planejado e o custo atual. É uma variável numérica que pode ser independente ou dependente (saída);
Duração da Linha de Base – Duração do projeto. Variável numérica independente;
Duração Atual – Duração atual do projeto. Usualmente, uma variável numérica independente;
Variância da Duração – A diferença entre a duração da linha de base e a duração atual;
Tipo de Contrato – variável categórica independente que define o tipo do contrato usado no trabalho do projeto (por exemplo: Preço Fixo, Preço Unitário, Taxa de Administração, etc.);
Número de Grupos de Stakeholders Relevantes – Variável numérica independente que reflete o número de grupos de stakeholders relevantes no projeto.
Alguns exemplos de variáveis de entrada são apresentados nas Figuras 05, 06 e 07.
Input Variables | Description | Unit | Range |
Figura 05 – Exemplos de Variáveis em Construção de Rodovias (SODIKOV, 2005) | |||
PWA | Predominant Work Activity | Category | New Construction Asphalt or Concrete |
WD | Work Duration | month | 14–30 |
PW | Pavement Width | m | 7–14 |
SW | Shoulder Width | m | 0–2 |
GRF | Ground Rise Fall | nillan | 2–7 |
ACG | Average Site Clear/Grub | m2/kin | 12605–30297 |
EWV | Earthwork Volume | m3/kin | 13134–31941 |
SURFCLASS | Surface Class | Category | Asphalt or Concrete |
BASEMATE | Base Material | Category | Crushed Stone or Cement Stab. |
Output Variable | |||
USDPERKM | Unit Cost of New Construction Project | US Dollars (2000) | 572.501.64-4.006.103.95 |
Description | Range |
Figura 06 – Exemplos de Variáveis Importantes para Edifícios (ARAFA & ALQEDRA, 2011) | |
Ground floor | 100–3668 m2 |
Area of the typical floor | 0–2597 m2 |
No. of storeys | 1–8 |
No. of columns | 10–156 |
Type of foundation | 1 – isolated |
2 – isolated and combined | |
3 – raft or piles | |
No. of elevators | 0–3 |
No. of rooms | 2–38 |
Cost of structural skeleton | 6,282469,680 USD |
Project Characteristics | Unit | Type of information | Descriptors |
Figura 07 – Exemplos de Variáveis para Construção de Edifícios (AIBINU, DASSANAYAKE & THIEN, 2011) | |||
Gross Floor Area (GFA) | m2 | Quantitative | n.a |
Principal structural material | No unit | Categorical | 1 – steel |
2 – concrete | |||
Procurement route | No unit | Categorical | 1 – traditional |
2 – design and construct | |||
Type of work | No unit | Categorical | 1 – residential |
2 – commercial | |||
3 – office | |||
Location | No unit | Categorical | 1 – central business district |
2 – metropolitan | |||
3 – regional | |||
Sector | No unit | Categorical | 1 – private sector |
2 – public sector | |||
Estimating method | No unit | Categorical | 1 – superficial method |
2 – approximate quantities | |||
Number of storey | No unit | Categorical | 1 – one to two storey(s) |
2 – three to seven storeys | |||
3 – eight storeys and above | |||
Estimated Sum | Cost/m2 | Quantitative | n.a |
Treinando Redes Neurais Artificiais
Quando o conjunto de dados está pronto o treinamento da rede pode ser iniciado. Duas abordagens podem ser usadas para o processo de aprendizagem: supervisionada ou treinamento adaptativo.
No treinamento supervisionado, ambas entradas e saídas são fornecidas e a rede compara os resultados fornecido pelo modelo com as saídas fornecidas. Isso permite o monitoramento da qualidade da convergência dos resultados da rede neural artificial com os valores históricos e sua habilidade de predizer a resposta correta.
No treinamento adaptativo, apenas as entradas são fornecidas ao modelo. Usando mecanismos auto organizáveis, a rede neural beneficia-se da aprendizagem contínua no intuito de se adaptar a novas situações e ambientes. Esse tipo de rede é comumente chamada Mapa Auto Organizável (MAO) e foi desenvolvido por Teuvo Kohonen (KOHONEN, 2014).
Um dos maiores desafios dos métodos de treinamento é decidir que tipo de rede deve-se utilizar e o tempo de execução do modelo em computadores. Algumas redes podem ser treinadas em segundos, mas em aplicações mais complexas, em que são utilizadas várias variáveis e casos, podem ser necessárias várias horas.
Os resultados do processo de treinamento são fórmulas complexas que relacionam as entradas (ou variáveis independentes) com as saídas (variáveis dependentes), como no gráfico apresentado na Figura 02.
A maioria dos pacotes comerciais comumente testam os resultados do treinamento com alguns pontos do conjunto de dados para avaliar a qualidade do treinamento. Cerca de 10 a 20% das amostras são utilizadas com o propósito de treinamento (Figura 08).
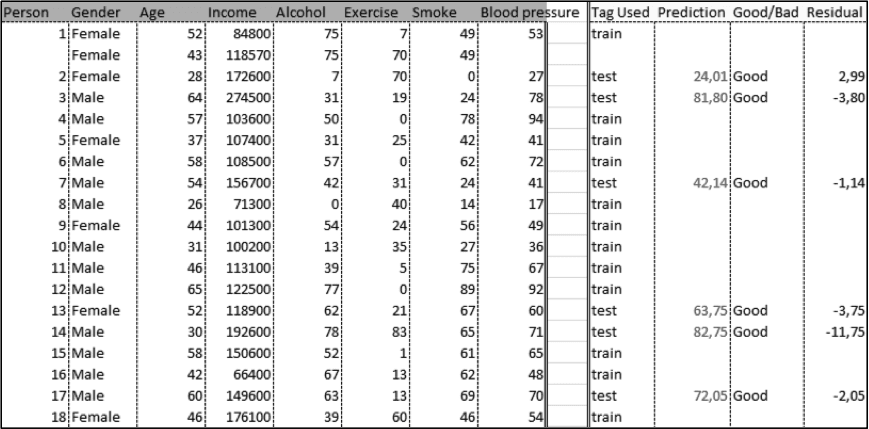 Figura 08 – Exemplos de resultados de treinamento para previsão da pressão sanguínea onde alguns dados são utilizados para testar as saídas do modelo (o software utilizado: Palisade Neural Tools)
Figura 08 – Exemplos de resultados de treinamento para previsão da pressão sanguínea onde alguns dados são utilizados para testar as saídas do modelo (o software utilizado: Palisade Neural Tools)
Resultados da Previsão
Depois do treinamento, o modelo está pronto para a predição de resultados. A informação mais relevante que deve ser foco de investigação é a contribuição individual de cada variável para os resultados previstos (Figura 09) e a confiança do modelo (Figura 10).
 Figura 09 – Exemplo de impacto relativo das variáveis, demonstrando que a variável Salário é responsável por mais de 50% do impacto na variável dependente (software usado: Palisade Neural Tools)
Figura 09 – Exemplo de impacto relativo das variáveis, demonstrando que a variável Salário é responsável por mais de 50% do impacto na variável dependente (software usado: Palisade Neural Tools)
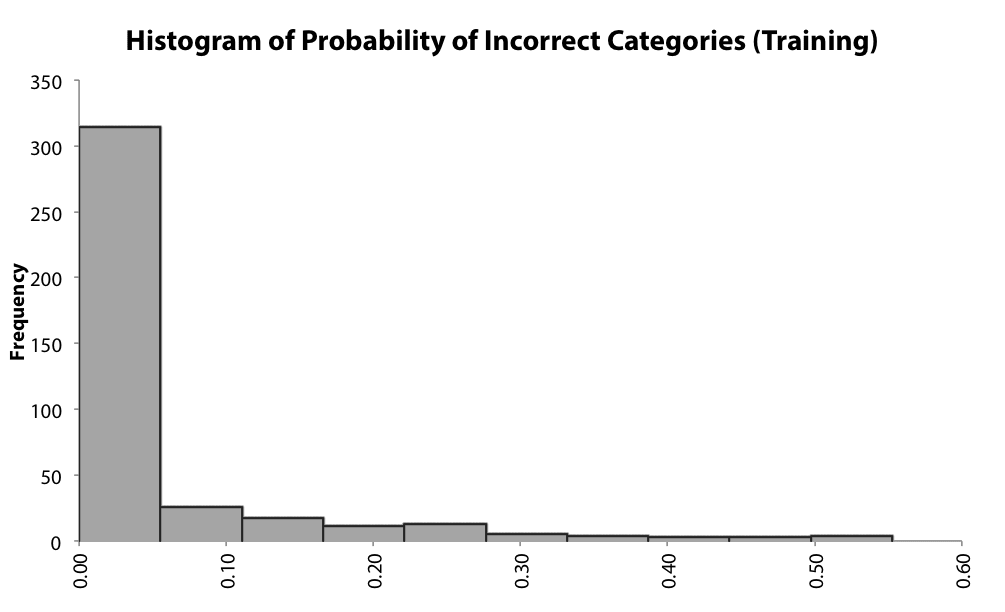 Figura 10 – Exemplo de histograma de Probabilidade de Categorias Incorretas evidenciando uma chance de 30% que 5% da previsões podem estar erradas (software usado: Palisade Neural Tools)
Figura 10 – Exemplo de histograma de Probabilidade de Categorias Incorretas evidenciando uma chance de 30% que 5% da previsões podem estar erradas (software usado: Palisade Neural Tools)
É importante enfatizar que uma rede treinada que falha em obter um resultado confiável em 30% dos casos é muito menos confiável que outro que falha em apenas 1% dos casos.
Exemplo de Modelagem de Custos usando Redes Neurais Artificiais
A título de exemplo do processo, um caso fictício foi desenvolvido para predizer o custo de gerenciamento do projeto a partir de dados históricos de 500 casos1. As variáveis utilizadas estão apresentadas na Figura 11.
O perfil dos casos usados para o treinamento está apresentado nas Figuras 12, 13, 14, 15 e 16 e o conjunto de dados está apresentado integralmente no Apêndice.
 Figura 12 – Distribuição dos casos por Local
Figura 12 – Distribuição dos casos por Local
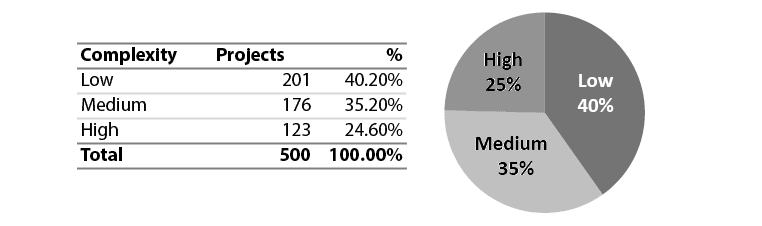 Figura 13 – Distribuição de casos por Complexidade
Figura 13 – Distribuição de casos por Complexidade
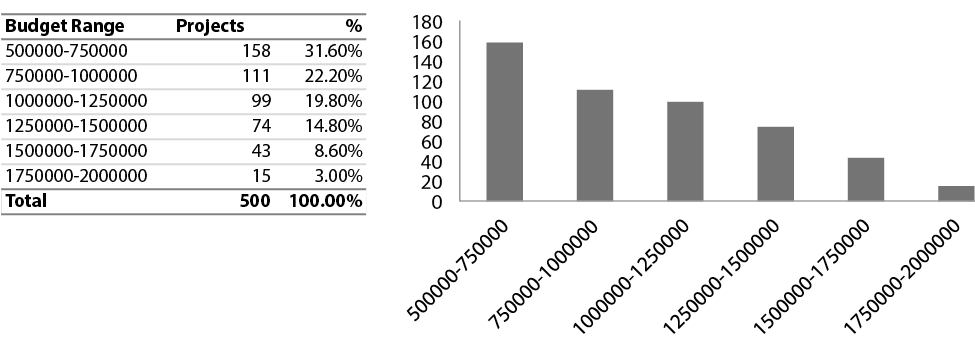 Figura 14 – Distribuição de casos por Orçamento do projeto
Figura 14 – Distribuição de casos por Orçamento do projeto
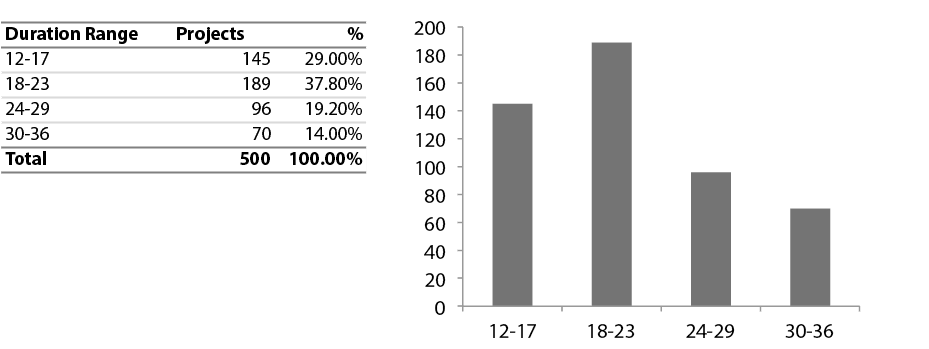 Figura 15 – Distribuição de casos por Duração do Projeto
Figura 15 – Distribuição de casos por Duração do Projeto
 Figura 16 – Distribuição dos casos por Grupos de Stakeholders Relevantes
Figura 16 – Distribuição dos casos por Grupos de Stakeholders Relevantes
O treinamento e os testes foram executados usando o software Palisade Neural Tools. O teste foi executado com 20% da amostra e com um modelo de previsões numéricas baseado em Redes Neurais com Regressão Generalizada. O resumo do treinamento da RNA está apresentado na Figura 17.
 Figura 17 – Tabela de Resumo do Palisade Neural Tools
Figura 17 – Tabela de Resumo do Palisade Neural Tools
O impacto relativo das cinco variáveis independentes está descrito na Figura 18, demonstrando que, no exemplo apresentado, mais de 50% do impacto do custo de gerenciamento do projeto está relacionado com a variável Orçamento.
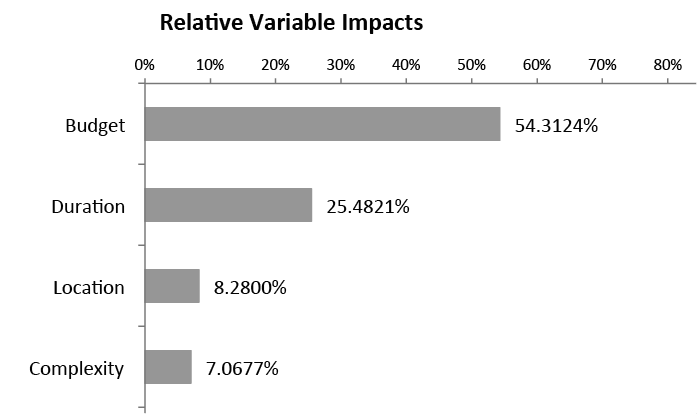 Figura 18 – Impacto Relativo das Variáveis
Figura 18 – Impacto Relativo das Variáveis
O treinamento e os testes foram então usados para prever o custo de gerenciamento de um projeto fictício com as seguintes características.
Após a execução da simulação, a previsão do custo de gerenciamento do projeto, baseando-se nos padrões do conjunto de dados, é $ 24.334,75, aproximadamente 3% do orçamento do projeto.
Conclusão
O uso de Redes Neurais Artificiais pode ser uma ferramenta útil para determinar aspectos do orçamento do projeto como o custo do gerenciamento do projeto, a estimativa do valor de uma proposta de um fornecedor ou o custo de um seguro de um equipamento. A Rede Neural permite a tomada de decisão com considerável precisão sem o emprego de um processo baseado em fórmulas ou algoritmos.
Com o recente desenvolvimento de ferramentas computacionais, o cálculo tende a ser muito simples e franco. Todavia, o grande desafio para obter resultados confiáveis está na qualidade das informações presentes. O processo por completo é baseado em dados históricos, e muitas vezes é exatamente essa a parte mais laboriosa e cara: conseguir um conjunto de dados confiáveis para o treinamento e teste do modelo.
Bibliografia
AIBINU, A. A., DASSANAYAKE, D. & THIEN, V. C. (2011). Use of Artificial Intelligence to Predict the Accuracy of Pretender Building Cost Estimate. Amsterdam: Management and Innovation for a Sustainable Built Environment.
ARAFA, M. & ALQEDRA, M. (2011). Early Stage Cost Estimation of Buildings Construction Projects using Artificial Neural Networks. Faisalabad: Journal of Artificial Intelligence.
BAILER-JONES, D & BAILER-JONES, C. (2002). Modeling data: Analogies in neural networks, simulated annealing and genetic algorithms. New York: Model-Based Reasoning: Science, Technology, Values/Kluwer Academic/Plenum Publishers.
BARTHA, P (2013). Analogy and Analogical Reasoning. Palo Alto: Stanford Center for the Study of Language and Information.
CHEUNG, V. & CANNONS, K. (2002). An Introduction to Neural Networks. Winnipeg, University of Manitoba.
INGRASSIA, S & MORLINI, I (2005). Neural Network Modeling for Small Datasets In Technometrics: Vol 47, n 3. Alexandria: American Statistical Association and the American Society for Quality
KOHONEN, T. (2014). MATLAB Implementations and Applications of the Self-Organizing Map. Helsinki: Aalto University, School of Science.
KRIESEL, D. (2005). A Brief Introduction to Neural Networks. Downloaded on 07/01/2015 at https://www.dkriesel.com/_media/science/neuronalenetze-en-zeta2-2col-dkrieselcom.pdf
MCKIM, R. A. (1993). Neural Network Applications for Project Management. Newtown Square: Project Management Journal.
SODIKOV, J. (2005). Cost Estimation of Highway Projects in Developing Countries: Artificial Neural Network Approach. Tokyo: Journal of the Eastern Asia Society for Transportation Studies, Vol. 6.
SPECHT, D. F. (2002). A General Regression Neural Network. New York, IEEE Transactions on Neural Networks, Vol 2, Issue 6.
SPITZIG, S. (2013). Analogy in Literature: Definition & Examples in SAT Prep: Help and Review. Link accessed on 06/30/2015: https://study.com/academy/lesson/analogy-in-literature-definition-examples-quiz.html
STERGIOUS, C & CIGANOS, D. (1996). Neural Networks in Surprise Journal Vol 4, n 11. London, Imperial College London.
SVOZIL, D, KVASNIČKA, V. & POSPÍCHAL, J. (1997). Introduction to multi-layer feed-forward neural networks In Chemometrics and Intelligent Laboratory Systems, Vol 39. Amsterdam, Elsevier Journals.
1 O exemplo foi desenolvido apenas para demonstração do uso das redes artificiais e não foi contruído a partir de dados reais. Todos os dados são fictícios e devem ser encarados apenas como exemplo.
Orçamento , Custos , Redes Neurais